您的位置:首页 >栏目首页 > 财报 >
作业帮发布银河大模型,C-Eval、CMMLU双榜排名第一
9月2日至6日,2023中国国际服务贸易交易会在北京举办,作业帮受邀参展,并正式发布自研银河大模型。在服贸会现场,银河大模型在智能解题、知识问答、中英文写作及AI伴学等方面的出色表现吸引了大量现场观众的互动体验。
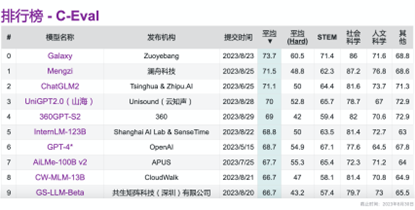
同时作业帮公布了银河大模型在C-Eval、CMMLU两大权威大语言模型评测基准的成绩。数据显示,作业帮银河大模型表现卓越,以平均分73.7分位居C-Eval榜首;同时在CMMLU榜单Five-shot和Zero-shot测评中分别以平均分74.03分及73.85分位列第一,成为首个同时在上述两大权威榜单平均分排名第一的教育大模型。
银河大模型作为作业帮自主研发的大语言模型,深度融合作业帮多年的AI算法沉淀和教育数据积累,是一款专为教育领域量身打造的覆盖多学科、多学段、多场景的教育大模型。它不仅具备高度的多学科知识解答能力,更能协助不同学段学生进行创意写作,同时还能够实现自主提问、陪伴式辅导等,助力学生个性化学习与成长。
作业帮银河大模型的综合实力在权威测评榜单中得到验证。作为全球最具影响力的中文评测集之一,C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,包含13948道多项选择题,涵盖52个不同学科和四个难度级别。根据C-Eval排行榜的最新数据显示,作业帮银河大模型以平均分为73.7分位居榜首。
在由MBZUAI、上海交通大学、微软亚洲研究院共同推出的CMMLU榜单中,作业帮银河大模型表现同样出色,在Five-shot和Zero-shot 测试中分别以74.03分及73.85分占据榜首。
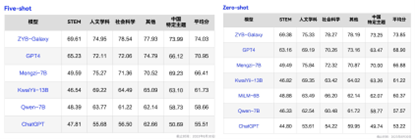
据了解,CMMLU共涵盖了67个主题,涉及自然科学、社会科学、工程、人文以及常识等。在CMMLU榜单中的卓越表现,再次印证了作业帮银河大模型在知识储备和语言理解方面的突出实力。
作业帮银河大模型不仅在中文方面表现优异,在英文方面表现同样不俗。由美国加州大学伯克利分校、哥伦比亚大学、芝加哥大学等高校联合打造的全球性大规模多任务语言理解评测基准MMLU,在集合了科学、工程、数学、人文、社会科学等领域的57个科目的评测中,作业帮银河大模型平均分高达71.88分,体现了其在英文领域的专业能力和问题解决能力。











